目录
对于前端同学来说, 业务组件库肯定不陌生,很多前端团队都会选择建设业务组件库来解决
- 业务组件跨项目复用的问题
- 同时统一代码实现,统一代码质量
从而提高业务的开发效率。但是我发现埋在明确需求之后,开始调研技术方案时,很多同学并不清楚要调研哪些技术点,怎么找到某个具体方向的解决方案,找到方案之后都需要试哪些 case, 以及怎么把这些方案集成在一起等等。
其实不用想那么复杂,你只需要按照以下三个技术实现的关键点搞定就可以了。
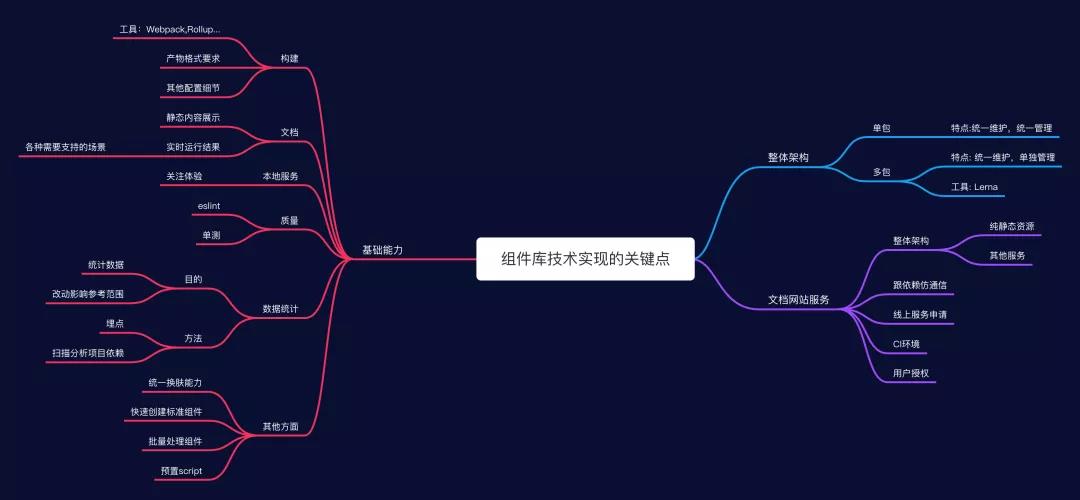
- 第一步:“搭地基”–业务组件库的整体架构设计
- 第二步:“建主体结构”–业务组件库的基础技术设计
- 第三步:“粉刷外立面”-- 业务组件库的对外文档服务
你一定觉得这三个点还是太宏观了,不好理解,所以接下来,我就分别介绍这三个关键点到底是什么。你可以参考这些关键点来进行相关技术调研
# 一. 业务组件库的整体架构设计
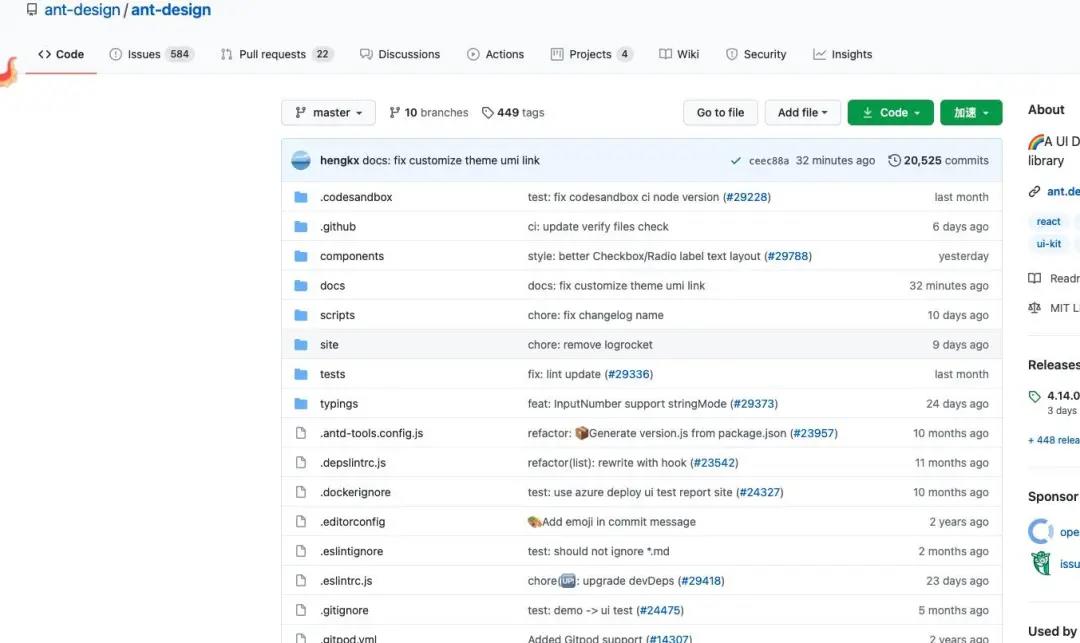
对于业务组件库的整体架构设计而言,核心问题是业务组件库的代码时如何来组织和管理。 首先,我们把代码仓库建好。业界一般会把同一类组件库用单个仓库的形式维护,并且把组件开发成 NPM 包的形式,这里的重点是,**你要考虑把所有的组件打包成一个大的 NPM 包,还是分割是一个个独立的小 NPM 包 。**不要小看这个问题, 这两种选择会使仓库的目录结构有不小的差异,进一步又会影响到后面组件的开发,构建,发布,实现的技术设计 单包架构
是什么
如果你选择把所有的组件看成一个整体,一起打包发布。这叫做单包架构。单个仓库,单个包,统一维护统一管理。比如 Antd
优点
它最大的优点是可以通过相对路径实现组件与组件的引用,公共代码之间的引用。
缺点
缺点就是组件完全耦合在了一起,必须把它作为一个整体统一发包。就算只改一个组件的一个非常小的功能,都要对整个包发布更新。 比如说 Antd,它就是作为一个整体的包来尽进行管理的。选择使用单包架构的话,那么你就必须提供按需加载的能力,以降低使用者的成本,你可以考虑支持 ES Modules 的 Tree shaking 的功能来实现按需加载的能力。当然你也可以选择另外一种方案,叫做"多包架构" 多包架构
是什么
每个组件彼此独立,单独打包发布,单个仓库多个包,统一维护单独管理。
.
├── lerna.json
├── package.json
└── packages/ # 这里将存放所有子 repo 目录
├── project_1/ # 组件 1 的包
│ ├── index.js
│ ├── node_modules/
│ └── package.json
├── project_2/ # 组件 2 的包
│ ├── index.js
│ ├── node_module/
│ └── package.json
...
优点
它最大的优势是组件发布灵活,并且天然支持按需使用,
缺点
缺点就是组件与组件之间物理隔离。对于相互依赖,公共代码抽象等场景,就只能通过 NPM 包引用的方式来实现。
在这些场景下的开发统一发布,相对来说没那么方便,多包架构在业界称之为 “Monorepo”.
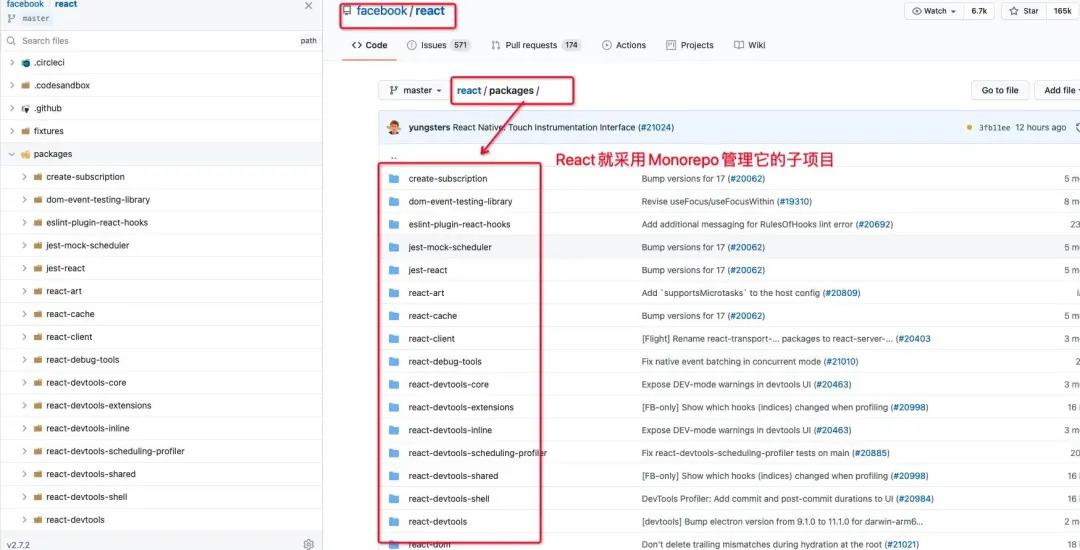
在前端领域,我们一般使用第三方库 Lerna 来维护这样的架构,Lerna 针对包之间有依赖的场景做了一些特殊优化,开发模式下,它会把所有存在依赖关系的包通过软链的形式连在一起,就可以很方便的本地开发联调。所以这就要求你考虑清楚,
- 组件库之间的组件是否有相互依赖的情况,如果有这种情况,就可以通过 Lerna 来进行处理
- 如果组件之间依赖特别验证,也可选择"单包架构"
# 二. 业务组件库的基础技术能力
当你确定了整体架构之后,就可以开始具体的功能点实现了。业务组件库要求整体框架提供五点基础的技术能力
- 构建能力 这需要我们可以提供构建产物的能力,这里有很多选择,可以选择 Webpack,Rollup Glup Grunt… 构建组件库推荐 Rollup, 构建项目推荐 Webpack. 这里需要特别注意产物的格式要求,像我们常用的 cjs, esm,umd 格式。
- 比如说如果你的组件考虑支持 node 环境, 像需要支持 ssr, 你就需要打包出 cjs 格式的代码
- 如果你的组件考虑支持
<script >标签引用,, 你就需要打包出 umd 格式的代码
然后就需要在对应的构建工具里进行配置 除此之外,还有几个非常容易遗漏的点,比如说
- 组件库 Bable 的配置是否与项目中 Babel 的配置重复
- 依赖包是打包到产物中,还是使用项目中的依赖包。如:lodash, moment…
- 依赖包的样式是否打包到产物中以及 Polyfill 的配置(这里以后再开一篇详细说明吧 😂)
文档 你需要提供一个可以实时运行的文档服务。包括支持静态内容的展示,以及可以查看源码的实施运行效果,这方面有很多优秀的开源库,比如 StoryBook&Styleguidist,Docz 这里你需要注意一个典型的错误行为,那就是调研的时候,只调研一些基础的功能就开始做选择,这样很容易给后面挖坑,你需要考虑尽可能多的情况。比如 有内部状态的代码示例能不能支持,例如弹窗类的组件,就需要在示例中做显示状态的切换 如果考虑放移动端组件,那么展示效果能不能支持,一般来说,移动端的示例,应该是通过 iframe 的形式运行在一个独立的页面里面。比如说,fiexd 定位的移动端组件是很常见的一种形式,如果不是 iframe,fiexd 定位的元素会铺满整个文档网页
章节配图 文档网站的依赖包跟组件的依赖包会不会冲突。假设两个依赖包版本不一致的时候,需要实现一个样式的隔离
本地服务 业界一般都是用文档服务来当本地服务的。启动本地的文档服务就可以查看运行的效果。这里你需要关注的是,本地服务的使用体验好不好,比如 说有没有热更新 编译速度够不够快 还有一个比较特别的点,有时候我们会在本地执行 build 构建。构建的产物跟本地生成的临时产物要能够做到相互隔离,互不影响
质量保证 一方面我们需要提供统一的 eslint 功能。保证基础的实现风格和质量 另一方面可以考虑引入单元测试的能力,业界也有很对优秀的单测框架,如 Jest ,Karma
数据统计 需要统计组件被多少项目使用,具体在哪个地方使用。这个能力的主要目的是提供统计数据以及了解改动的参考影响范围。 你可以通过
- 组件内增加埋点 来进行统计。埋点方案会有一个时效性的限制,在你统计的时间周期内,如果说该组件的功能没有用户用到的这种情况是统计不到的
- 定时扫描分析所有代码仓库依赖来进行统计。可以搜索关键词 dependency tree
除了上诉几点能力以外,业务组件库还要求整体框架提供统一换肤的能力,快速创建新标准组件的能力,批量处理组件的能力,以及预置命名等等
像发包的命令,自测的命令,自动生成 ChangeLog 等等这样的命令。
# 三. 业务组件库的对外文档服务
当基础的能力都准备好之后,我们最后再关注一下对外的一个输出。也就是我们的文档网站。这里我们需要把它当成一个线上服务来搭建,这里需要考虑一个具体的架构是什么
- 可能是纯静态资源
- 配到的 CI 怎么搭建
# 总结
以上就是业务组件库技术实现的几个关键点,下面进行一个思维导图的总结